
- August 17, 2019
- by admin
- Case Study
- 0 Comments
Everything you wanted to know about the Robots txt File and how to use it.
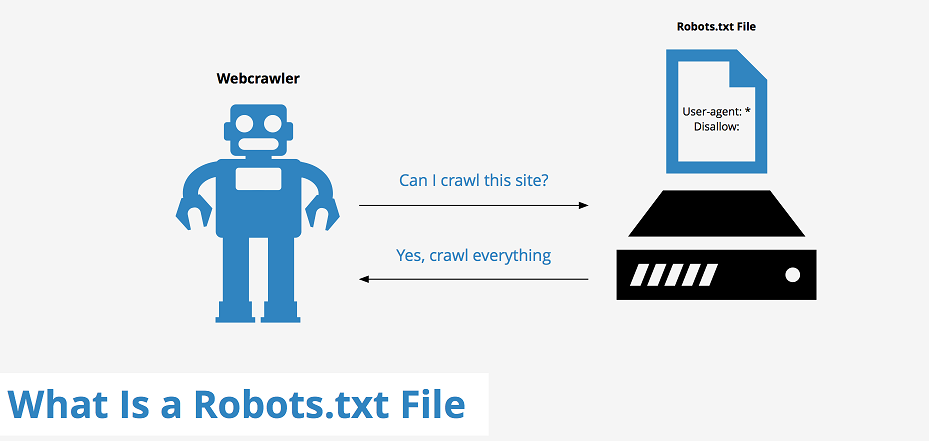
A robots txt file is a utility that can be used to wield further control over the Search Engine bots. A crucial aspect of any Search Engine Optimization strategy is controlling what the search engine spiders can see or cannot see on your website. This allows you to prevent the spiders from crawling and indexing duplicate content while ensuring that the search engines focus only on your website’s most important and relevant content.
Beginner’s guide to Robots TxT File
This is easily achieved with the use of a robots txt file. This is a simple text file that contains instructions required for the spiders to help them understand how to crawl your website. Although deploying this file is fairly easy, there is often some confusion surrounding the role and the usage of this file. This beginner’s guide to robots.txt attempts to dispel some of this confusion and show you how to use a robots.txt file effectively.
A robots.txt file is intended to let search engine spiders and other crawlers know what pages they can NOT index rather than telling them what pages they can. This ensures that the spider’s time on your website is spent efficiently indexing important content rather than wasting it by looking at obscure pages like:
Backend admin-only content
PHP, Perl and other scripts
Shopping cart checkout pages
Print version of pages and posts
Password protected directories
Local (on-site) search result pages
Forum member profile pages
These are the pages that have no business showing up on Search Engine Result Pages (SERPs) or could be problematic for to the spiders.
Controlling the Spiders with Robots.txt File
You can think of the robots txt file as the spider’s tour guide for your website. It lets the spiders know where to find the content that you do NOT want to be indexed. It can also let the spiders know how frequently to crawl your website and show them where to find the XML sitemap for your website. This results in a much quicker and more efficient indexing of your website.
When a search engine spider, or any other crawler, visits your website, the first thing it does is take a look at your robots.txt file to understand which pages it should not index. If you prefer the bots to crawl and index your entire website and associated resources, then you do not need this file at all. Remember…
The primary use of a robots txt file file is to prevent search engines from indexing certain parts of your website.
Guide to Robots Txt File – A Beginner’s Primer
If you are setting up your robots.txt file for the first time, be advised – avoid making too many changes in one go. Why? You want to keep track of the effect of these changes on your site and if you make a mistake, you will know what changes to roll back. It is important to take baby-steps because if you mess up your site’s search engine visibility, you can lose a significant amount of traffic to your website. It’s a good idea to keep a backup of this file in case you want to revert to an earlier version.
Now, let’s get started. A Robots TxT File must be located at the root of your domain. This is how it should look:
http://www.yourdomain.com/robots.txt
Putting it in a directory on your domain like this:
http://www.yourdomain.com/directory/robots.txt
…won’t work.
Further, every site needs just one robots.txt file which is all you need to restrict crawler access to parts of it. However, if you have subdomains in use (remember: subdomains, not subdirectories) then each subdomain should have its robots txt file as well. For example:
http://www.blog.yourdomain.com/robots.txt
Also, if your website has both the secure and non-secure versions in use (https and http versions), and if the root directory changes in response to either of these protocols then you need a separate robots.txt for both these versions.
If you are working with a Content Management System, then you may already have a robots.txt file. Look into your site’s root folder to confirm this. If not, you can create a new robots.txt file using a simple tool such as Notepad (or, Notepad++) on a Windows machine or TextEdit on a Mac. Do not use a rich text editor like MS Word as it can introduce some special characters that may not work. A very simple robots.txt file may contain instructions similar to this:
User-agent: *
Disallow: /this-directory-will-be-blocked/
I will explain what these two lines of text mean shortly.
A Note on Robots.txt and Google Page Rank
An important thing to be aware of, while blocking a URL via robots.txt, is that Google does not pass PageRank through any URL that is blocked via Robots txt file. What this means is that if you have some good high PR links coming into a URL on your site that is blocked via robots.txt, none if this PR will be passed on to your website. It will be lost. This is true not just for Google, but for any other search engine that uses inbound links as a ranking factor and respects the instructions from a robots.txt.
In situations like these, instead of using robots.txt to block such URLs, you can use the “noindex” tag to prevent them from showing up on SERPs. This is the code you need to add to these pages:
The robots.txt will then allow the spiders to crawl and index these URLs while allowing the Page Rank to flow through to your website, but because of the “noindex’ tag this content will not appear on SERPs.
How to use Robots.txt
Robots.txt file is the most effective way of preventing search engines from indexing duplicate content on your website. Most Content Management Systems automatically create content that can be deemed as duplicate by search engines. Besides, there may be situations in which you would want search engines to stay away from an entire section of your website (like when you are working on a section that is still under development).
Robots.txt is also handy when you are looking to block access to indexable content that has no business being on SERPs. A common example is a local (on-site_ search result page for your website. A typical search result page for a website may look like this:
http://yourwebsite.com/cgi-bin/s/search.php?&Terms=Ford+Ecosport&results=10
To prevent (or, disallow) an entire directory or a section of your website, you can add the following lines of text to your robots.txt file:
User-agent: *
Disallow: /cgi-bin/search/
Let’s deconstruct the instructions:
The User-agent part of the instruction specifies the search engine bot you want to talk to. In the above example, we use an asterisk (*), which is the wildcard symbol for all spiders. You can also specify a particular spider. For Google’s spider, known as the Googlebot, the code would look like this:
User-agent: Googlebot
Disallow: /cgi-bin/
Similarly, for Bing, the code could be modified as following:
User-Agent: Bingbot
Disallow: /cgi-bin/
For Yandex you could use the Yandexbot instead. For a list of all such crawlers, visit the following URL: http://www.useragentstring.com/pages/Crawlerlist/
In order to block any other part of your site, just replace cgi-bin in the above examples with the name of the directory that contains the pages you want to block. For example, to block search engines from indexing pages in the admin directory, you can use:
User-agent: *
Disallow: /admin/
To block multiple directories, you can use multiple lines of code each specifying a directory:
User-agent: *
Disallow: /admin/
Disallow: /cgi-bin/
Disallow: /pdfs/
What are Robot User-Agents
By now you understand that different Search Engines have unique User-Agents that describe their bots. Most search engines have more than one bot User-Agent for different tasks. As an example, while Google’s primary Bot is called the Googlebot, it has another bot known as the Googlebot-News, that only crawls content related to news for the Google news feed. In most cases you would need to specify just the primary User-Agent to control site crawling and indexing.
In some specific cases, for example, you may want to specify a bot other than the primary bot for specific indexing patterns. For example you can control what content the Google’s AdSense Bot has access to, if that content is going to be different from what the primary bots see. You can mix and match various User-Agents as follows:
User-agent: *
Disallow: /folder-name/
User-agent: Mediapartners-Google
Allow: /folder-name/
CrawlerUser-Agents for Popular Search Engines
All search engine bots maintains a list of their available bots. The ones for the popular search engines are listed below:
Google
Bing
Baidu
Yandex
In most cases, however, you would want all User-Agents to treat your website in a similar fashion and the wildcard (*) User-Agent is all you would ever need.
How to Block Dynamic URLs from Being Indexed via Robots.txt
Most CMS based sites generate dynamic URLs (often based on user inputs) that contain multiple parameters. There is a great chance of these dynamic URLs resulting in duplicate content issues. You can disallow such pages from being crawled by using the wildcard parameters in the URLs listed in your robots.txt file. Here’s an example:
Following are some sample URLs created dynamically within a CMS, in response to user queries. All these URLS contain the same content but the URLs are different with some extra parameters apearing after the “?” in the URL. To a search engine, these are all unique URLs but with similar content, resulting in duplicate content issues:
/coursepage/seo.php?propcode=FLAGS&SRCH=rnk
/coursepage/seo.php?propcode=FLAGS&vr=10
/coursepage/seo.php?propcode=FLAGS
=======
The Problem with Duplicate Content
Search engines only want to return a single copy of a page to users, so if it find multiple copies of a page listed at different URLs, they’ll remove all but one from their index. The problem is, they might not remove the copy you want them to! Robots.txt lets you control that.
=======
These pages are all copies of the same page – the “seo.php” page, in the “courses” section of the website. But only one of these needs to be indexed. Once you have decided which one of these pages you would like to be indexed, you can keep the bots from indexing the remaining pages by adding the following to your robots txt file:
User-agent: *
Disallow: /*&
Let’s break it down:
First, we use the asterisk (*) wildcard symbol to specify that we want all crawlers to follow these instructions. Next, in the second line we have a /*& which means that these crawlers are supposed to be on the lookout for URLs that contain:
a forward slash (/),
followed by any number of characters (*),
and then containing an ampersand character (&),
…and disallow them from being indexed.
This will result in the crawlers blocked from indexing the first two URLs from the example above:
/coursepage/seo.php?propcode=FLAGS&SRCH=rnk
/coursepage/seo.php?propcode=FLAGS&vr=1
…while the third URL will be the one to be crawled and indexed:
/coursepage/seo.php?propcode=FLAGS
This is because the third URL does not match the blocking pattern we used – it does not have the & in the URL as is the case with the other two URLs.
Similarly, if you need to have all search engines ignore any URL that contains a “?” (which is the case with most dynamic URLs), you can use the following:
User-agent: *
Disallow: /*?
Along similar lines, you can use the (*) wildcard character to bulk block all directories that match a caertain pattern. For example, the following lines of code in your robots.txt would block all directories that start with the word print:
User-agent: *
Disallow: /print*/
This might come in handy if you are looking to block the print-versions of your pages and thus prevent duplicate content. Just identify the structure which your own website uses and use the wildcard to block it appropriately.
Warning: You must be aware of how the URLs on your website are being constructed before applying any blocking rules or you may accidently wind up blocking access to pages that you DO want indexed. This may result in search engines removing entire sections of your website from their result pages.
Continuing with the example above, the code would also stop the indexing of a URL that looks like:
http://www.yourdomain.com/products/printing-press/
…because it matches the disallow pattern in the robots.txt.
Another important thing to note is that if you’re blocking all URLs that contain the ampersands (&) character, but you need the spiders to be able to crawl a single URL that contains an ampersand, then you need to pecifically “Allow” this specific URL within your robots.txt file thus:
User-agent: *
Disallow: /*&
Allow: /vacationrentals/rates&seasons/details.html
This tells the search bots to avoid all URLs that contain an ampersands except the URL specified in the Allow line. Remember that the default setting for search engine spiders is to crawl all pages. You need to use Allow ONLY in cases where a large section of a site is disallowed but you want to allow access to a special page or section within it. Needless to say, Allow is one of those robots.txt parameters that you’ll rarely use except in special circumstances.
Following from the discussion above, you can now disallow an entire folder while permitting selected pages within that folder to be indexed by specifically allowing them:
User-agent: *
Disallow: /admin/
Allow: /admin/page-in-admin-folder.htm
